Benchmarked against official
regulatory certification standards
Not simulated benchmarks — validated against the actual test suites used for regulatory approval.
Efficiency in ADAS/AD Verification
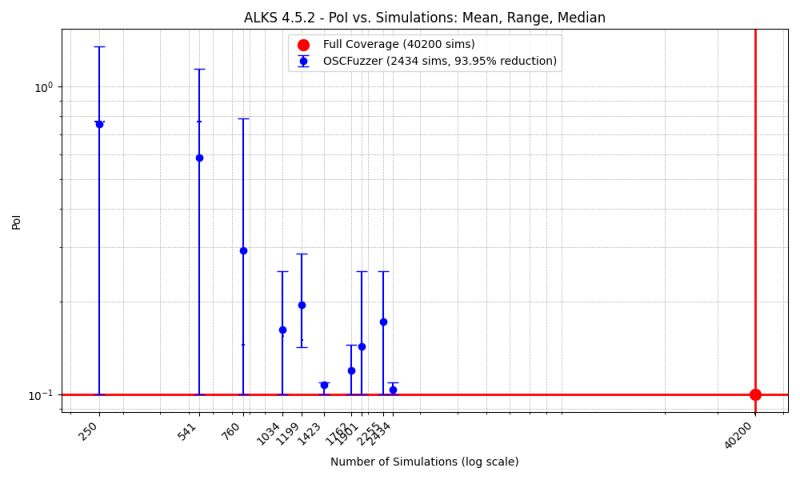
Addressing the “needle in a haystack” challenge of higher-autonomy certification. Tempero’s verification suite identified the only 2 critical safety cases out of over 40,000 valid scenarios — using a fraction of traditional computational resources.
cost reduction
traditional
in full space
1M+ Scenarios
Generated to explore the complete configuration space of the certification scenario
40,000+ Valid
Simulation scenarios identified within regulatory constraints
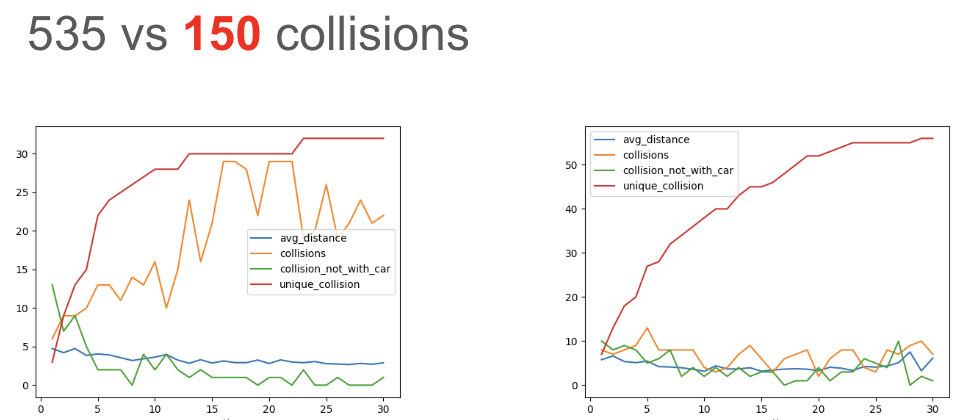
Fine-Grained Risk Assessment of AEB in Urban Settings
Tempero conducted a detailed assessment of Automated Emergency Braking in two urban settings with varying traffic densities — demonstrating context-specific safety evaluation that global statistics cannot provide.
virtual simulations
compared
Setting td1 — AEB effective
Setting td2 — AEB limited
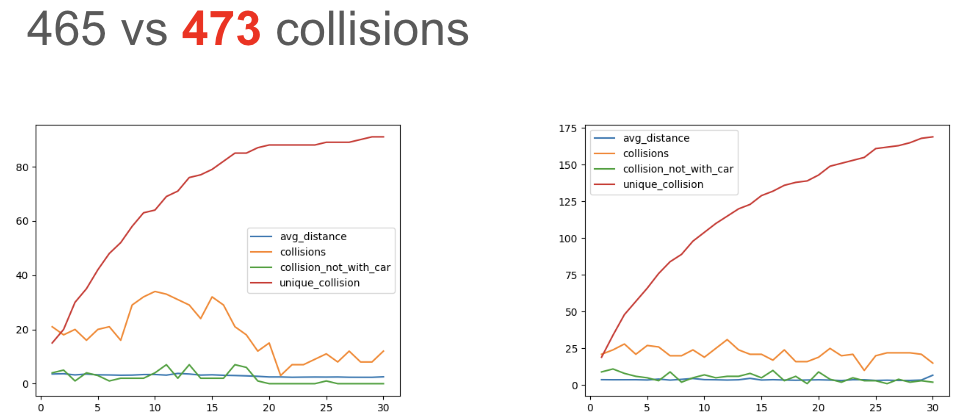
Context-Specific Insight
Unlike global statistics — results are tied to specific traffic and environmental conditions.
V2I / V2V Ready
Assessment accounts for new mobility contexts including connected infrastructure